DSSM(Deep Semantic Structrured Model)
结构
可以在检索的场景下,使用点击数据来训练语义层次的匹配
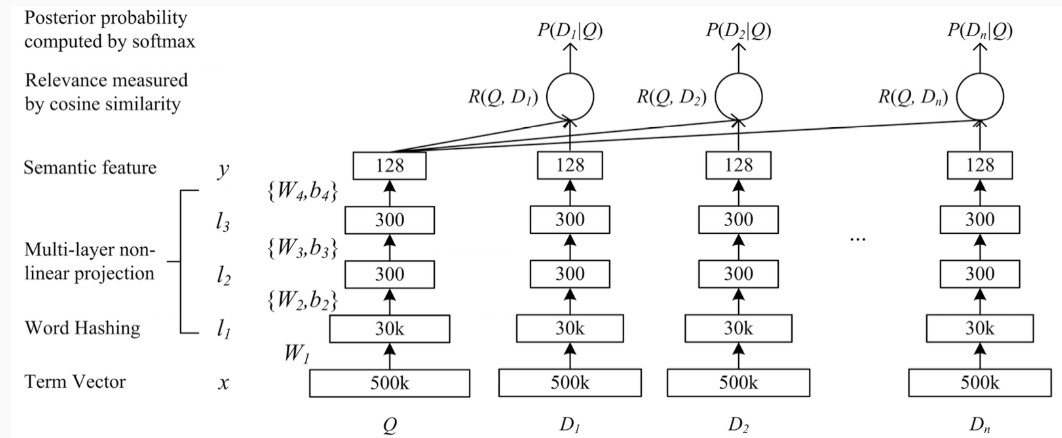
- 输入为一个query和这个query相关的doc,这里的特征可以使最简单的one-hot形式,我们要计算query和doc的相似度。
- one-hot编码会导致维度过大以及OOV问题
- 所以采用word-hashing的方法
- 之后就是传统的神经网络
$$ l_i = f(W_il_{i-1} + b_i) $$ - 得到y之后,就可以用cos函数计算query和doc之间的相似度了。
Word Hashing
Word Hashing是paper非常重要的一个trick,以英文单词来说,比如good,他可以写成#good#,然后按tri-grams来进行分解为#go goo ood od#,再将这个tri-grams灌入到bag-of-word中,这种方式可以非常有效的解决vocabulary太大的问题(因为在真实的web search中vocabulary就是异常的大),另外也不会出现oov问题,因此英文单词才26个,3个字母的组合都是有限的,很容易枚举光。
那么问题就来了,这样两个不同的单词会不会产出相同的tri-grams,paper里面做了统计,说了这个冲突的概率非常的低,500K个word可以降到30k维,冲突的概率为0.0044%
但是在中文场景下,这个Word Hashing估计没有这么有效了
因为直接使用了word hashing,因为无法记录上下文信息
训练过程
得到了query和每个doc的相似度之后,就可以得到后验概率 $ p(D|Q) $
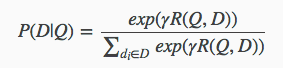
最终他需要优化的损失函数为:
$$ L(Λ)=−log∏(Q,D+)P(D+|Q) $$
D+表示被点击的文档,这里就是最大化点击文档的相关性的最大似然