Semantic textual similarity
Model:
ESIM
- 编码模块:使用bi-lstms编码文本,取最后一层的输出。
- 局部推理模块
- 使用soft-attention的方法,得到整个句子的分布式表达。每个time step对应的权值大小是对应编码的向量的乘积。作者并没有使用额外的参数去求这个softmax的权值。
- 推理合成部分
- 得到经过softmax的每个word的表达,然后通过concat原始word编码,attention编码,二者的差,二者的点乘。concat到一起
- 输入到下一层的inference Bi-LSTMs
- 输出模块
- 然后,对Bi-LSTM的输出,在time维度上取max pooling,average pooling.将结果concat到一起,输入到MLP中。
BIMPM
word representation Layers:
- 同时使用预训练的词向量,和cnn+lstm的character embedding
Context Representation Layer
- 使用bi-lstm编码得到双向的每个time-step的context embedding
Matching Layers
使用了四种匹配策略,可以看做是不同的Attention方法。
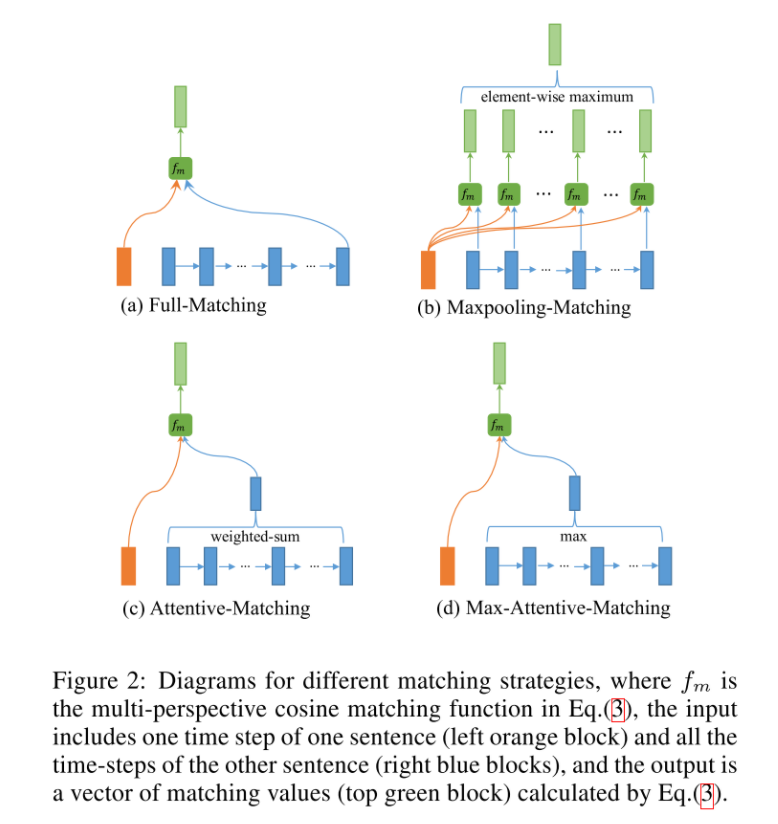
Full-Matching
- P中每一个前向(反向)文法向量与Q前向(反向)的最后一个时间步的输出进行匹配。
Maxpooling-Matching
P中每一个前向(反向)文法向量与Q前向(反向)每一个时间步的输出进行匹配,最后仅保留匹配最大的结果向量。
Attentive-Matching
先计算P中每一个前向(反向)文法向量与Q中每一个前向(反向)文法向量的余弦相似度,然后利用余弦相似度作为权重对Q各个文法向量进行加权求平均作为Q的整体表示,最后P中每一个前向(后向)文法向量与Q对应的整体表示进行匹配。
Max-Attentive-Matching
与Attentive-Matching类似,不同的是不进行加权求和,而是直接取Q中余弦相似度最高的单词文法向量作为Q整体向量表示,与P中每一个前向(反向)文法向量进行匹配。
输出层:
- Matching Layer输出的匹配向量经Aggregation Layer双向LSTM处理后作为最后预测层的输入,预测层利用softmax函数输出预测结果。
MPCNN
(15年的论文,但是试验效果非常好)
完全使用CNN来做文本匹配。CNN虽然对时序信息处理的不好,但是能够捕获到关键的信息。CNN 用作 MT
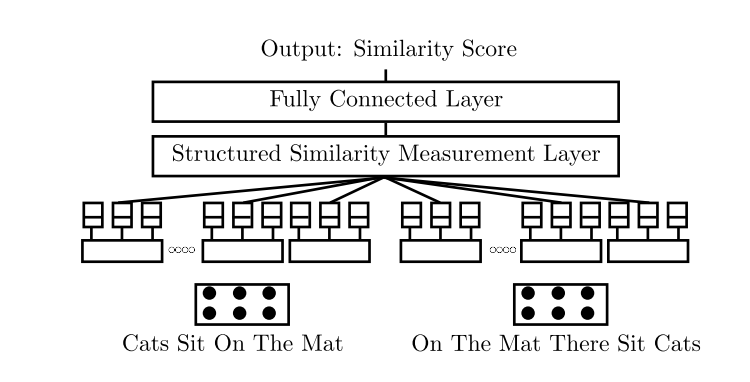
模型介绍
Sentence Model:
将文本转化成一个表达,使用多种类型的卷积核和pooling方法做
- 多种卷积方式:
- 对整个sequence 的word embedding使用卷积(对于time step这个维度进行卷积运算)
- 对word vectors维度使用卷积,得到不同粒度下的信息
- 多种pooling方式
- max, min, mean
- Multiple Window Sizes
- 多种卷积核大小
- 多种卷积方式:
Similarity measure Layer
同样使用多种相似度评测的方法
- 得到两个text的分布式表达,通过计算余弦距离,欧几里得距离,绝对距离(element-wise)
- concat到一起
输出层
- 全连接层和softmax层
在天池的CIKM文本匹配比赛中,这个模型的效果非常好。