Exploring the Limits of Language Modeling
论文主要讨论了当前的RNN模型在大规模的语言建模方面的进展。
Introduction
LM是NLP的核心任务,可以准确将句子的分布模型可以编码句法结构,而且能够提取到预料中可能包含的到两信息。
当训练大量的data时候,LM能够简洁的抽取到训练数据的知识编码。
最近,大规模的LM的研究表明, RNN和N-grams的信息结合起来是很好的,因为它可能有不同的有优势来补充N-grams模型。
本文的贡献:
- 对当前的大规模的LM模型尽量进行归一化
- 设计了一种基于character level 的CNN 的softmax loss,train时候很有效。和full softmax结果相近,但是参数更少
- 产生了新的state-of-the-art的结果。由51.3降到了30.0
- 对多个模型进行ensemble,得到结果进一步降到了23.7
- 分享模型帮助更多的研究
Related Work
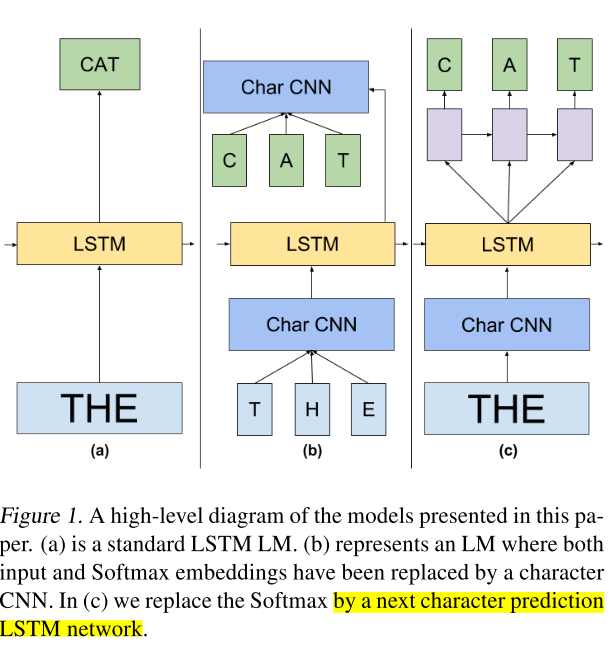
2.2 Convolution Embedding Models
Incorporating character-level inputs to build word embedding for various NLP problems
character embedding信息的方法:
使用双向的LSTM对字符进行运算,最终输出的state vector concat到一起输入到模型中。
使用CNN对character 进行卷积,取max pooling,然后丢入到一个2层的Highway network中。
2.3 Softmax Over Large Vocabularies
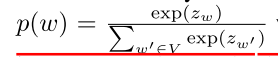
当Vocabulary很大的时候,这种方法的计算量是巨大的。
目前已经提出的方法:NCE,importance sampling, Hierarchical Softmax等
,本论文发现,Importance Sampling更有用,解释了它和NCE的联系。
LM Improvements
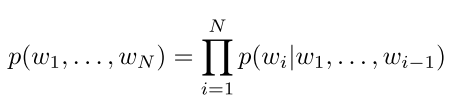
联合概率公式:
NCE & Importance Sampling

Sampling方法适用于训练阶段,它能够产生loss的近似值,但是更容易计算。
NCE是提出一个代理二分类的任务,其中分类器被训练为区分真实数据(正样本)和来自任意分布的样本(负样本)
如果我们知道了noise 和data的数据分布,优化这个二分类classifier就是: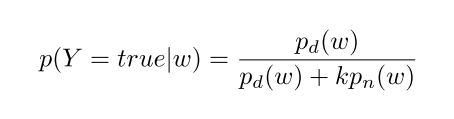
Y是二元结果
k表示negative samples的数量
$p_d$和$p_n$表示data和noise的分布。
The other 方法是基于Importance Sampling(IS)
该方法提出通过重要性抽样直接估计分配函数(包括所有单词的综合)和估计值。
NCE方法有非常完美的理论证明:随着噪声样本k的数量增加,NCE导数趋近于softmax函数的梯度。Mnih 和 Teh (2012) 认为抽取25个噪声样本就足以达到常规softmax方法的效果,速度能提升大约45倍。
NCE与IS的相似性
jozefowicz认为NCE与IS的相似点不仅在于它们都是基于采样的方法,而且相互之间联系非常紧密。NCE等价于解决二分类任务,他认为IS问题也可以用一个代理损失函数来描述:IS相当于用softmax和交叉熵损失函数来优化解决多分类问题。他觉得IS是多分类问题,可能更适用于自然语言的建模,因为它迭代更新受到数据和噪声样本的共同作用,而NCE的迭代更新则是分别作用。事实上,Jozefowicz等人选用IS作为语言模型并且取得了最佳的效果。
CNN Softmax
使用普通的softmax计算的logit值是:
$$ z_w = h^T e_w $$
使用CNN来做e_w:
$$ e_w = CNN(chars_w) $$
使用softmax得到的e_w之间是相互独立的,但是使用CNN-softmax得到的的词向量都是具有平滑的映射关系的。所以,需要小的learing rate进行训练
但是,Char-CNN的缺点是缺乏对于一词多义和具有相同拼写的单词的区分,因此增加一个correction factor。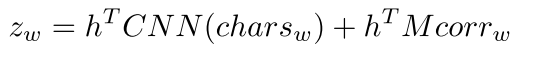
其中M是投影低维嵌入矢量corrw的矩阵,其返回到投影的LSTM隐藏状态h的维度。
优势:
- 参数更少,相比于使用Embedding方法
- OOV单词更容易scored
Char LSTM Prediction
A class of models that solve this problem more efficiently are character-level LSTMs
使用char lstm来产生word representation。
因此,我们通过将字级LSTM隐藏状态h输入到一个小LSTM中来预测目标单字每次一个字符,从而将单词和字符级模型结合起来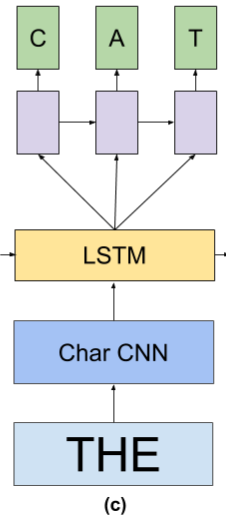
在word representation输入到LSTM(黄色)之后,产生了一个hidden state h,输入到另外一个小的Character-level LSTM(紫色),每次 产生一个character
Experiment
Dataset
1BWord Benchmark data se
Model setup
- PPL
- 不对数据集进行任何预处理
- 采用character作为输入和输出,每个word都是作为一串character IDs。word会被处理为具有特殊标识begin和end的形式。最大长度为10.
eg:
cat会别转换成”$cat^@@@@@”
实验表明,最大单词的长度为50的时候,效果最好
我们使用256个characters 。非ascii符号表示为字节序列
Model Architecture
LSTMs,带有一个project layers(eg: a bottleneck between hidden states), 在20-steps truncated BPTT方法训练效果最好。
使用Dropout在每一个LSTM层,LSTM forget gates bias设置为1.0,
使用large number的features 4096, 然后使用线性变换,将其变化到符合LSTM project sizes。
训练参数
Adam + LR=0.2
LSTM最大计算展开长度为20
batch_size = 128
clip gradient = 1
使用较大的Noise Sampling:8192。
Result 和分析
size matter
Layer层数很重要,试验表明,两层LSTM效果最好,8192 + 1024的state维度
regularization 很重要
使用dropout可以提升结果
对于少于4096或者更少的unit的LSTM,dropout = 0.1比较好
对于更多unit的LSTM,dropout = 0.25是更好的选择。
Importance Sampling 更有数据效率
Word embedding和Character CNN
使用Character CNN的优势是可以让Embedding layer得到任意单词的表示,实验表明,char-cnn是可行的,不会降低性能。
另外,char-cnn具有更少的参数,
Smaller model with CNN Softmax
Conclusion
Thus, a large, regularized LSTM LM, with projection layers and trained with an approximation to the true Softmax with importance sampling performs much better than N-grams.