Notes on Noise Contrastive Estimation and Negative Sampling
结论:
NCE在计算正负样本的条件概率大小的时候,考虑了负样本和分布情况,预测的结果不仅和正样本有关,同时和负样本的分布也有关系。负样本的label是 soft label
但是,而Negative没有考虑负样本的分布,直接将正负样本都当做是已经存在的(存在即是必然),抽样出来的负样本就是假设已经存在的负样本。对NCE的进一步简化。负样本的lable是hard label
Abstract
在进行估计LM的参数估计的时候,因为需要评估整个字典的每个word的概率,所以计算起来非常困难。有两种相关的策略用来解决这个问题:Noise ccontrastive estimation 和 Negative Sampling
这篇论文指出了,尽管二者非常相似,但是NCE是渐进无偏的一半参数估计技术,而Negative sampling可以理解为一个二分类模型,他对于学习word representation非常有用,但是不能作为一个通用的方法。
Introduction
对于LM需要估计下一个单词w。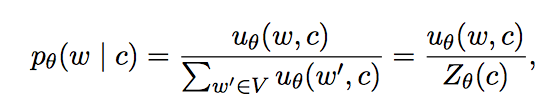
和前面所叙述的一样,vocab太大,会导致计算概率非常困难。
NCE和NS方法都是将这种计算代价大的方法转化为二分类的代理问题,使用相同的参数,但是更容易进行计算。
Noise contrastive estimation (NCE)
NCE将语言模型估计问题减少为估计概率二元分类器的参数的问题,该概率二元分类器使用相同的参数来区分样本与经验分布样本与噪声分布产生的样本
NCE方法两类数据产生过程如下:
- 从真实数据分布p(c)中采样采样一个数据c,
从数据的真实分布$p(w|c)$得到一个真实样本,标记为1
从’noise’ 分布 q(w)选择k个noise samples ,标记为0.
对于给定正负样本的联合概率就可以表示为:
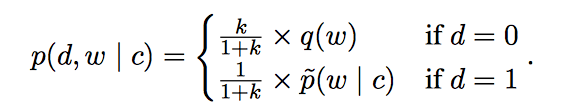
转转化为条件概率: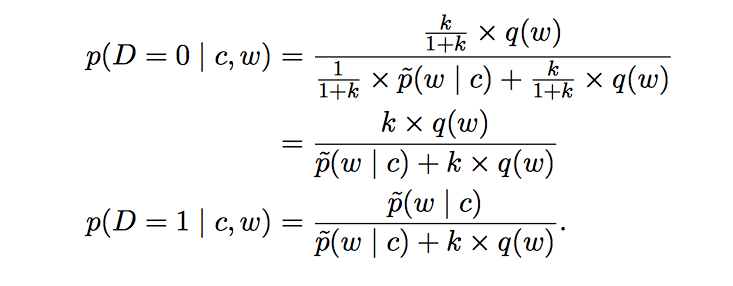
这些方程式是根据数据的真实分布做出的。
NCE是将经验分布$\tilde{p}$用模型预测分布$p_{\theta}$替换,$\theta$选则能让条件分布的似然概率最大的权值。
为了减少partition function(1式中的分母部分),NCE做了两个假设:
- partition function的大小Z(c)可以看做是参数$z_c$的估计,所以,对于每个c,NCE都会引入一个参数
- 将$z_c$固定为1的时候,最有效。
然后就可以得到经验分布: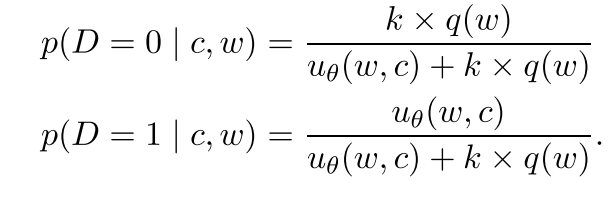
然后就可以得到Loss function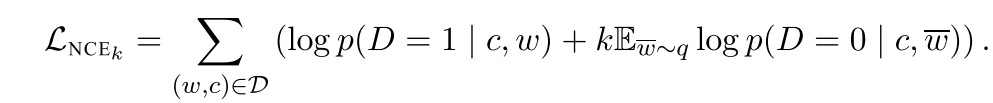
Negative Sampling
NS方法定义条件概率为: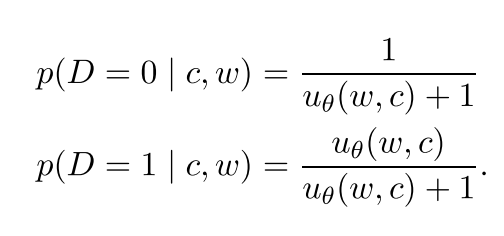
等价于NCE中k取了vocab大小,而且单词的分布式均匀分布的。
参考了一个新的论文:https://arxiv.org/pdf/1402.3722.pdf
考虑到一个单词对(w, c) of word and context.
我们的目标实参数最大化所有观测的结果(正确的单词对)来自于data(预测为1)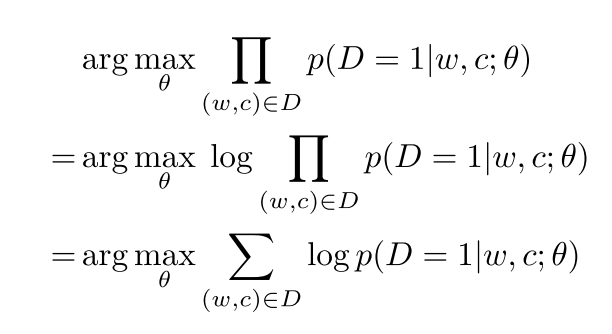
NCE在计算正负样本的条件概率大小的时候,考虑了负样本和分布情况,预测的结果不仅和正样本有关,同时和负样本的分布也有关系。
但是,而Negative没有考虑负样本的分布,直接将正负样本都当做是已经存在的(存在即是合理),抽样出来的负样本就是假设已经存在的负样本。对NCE的进一步简化。